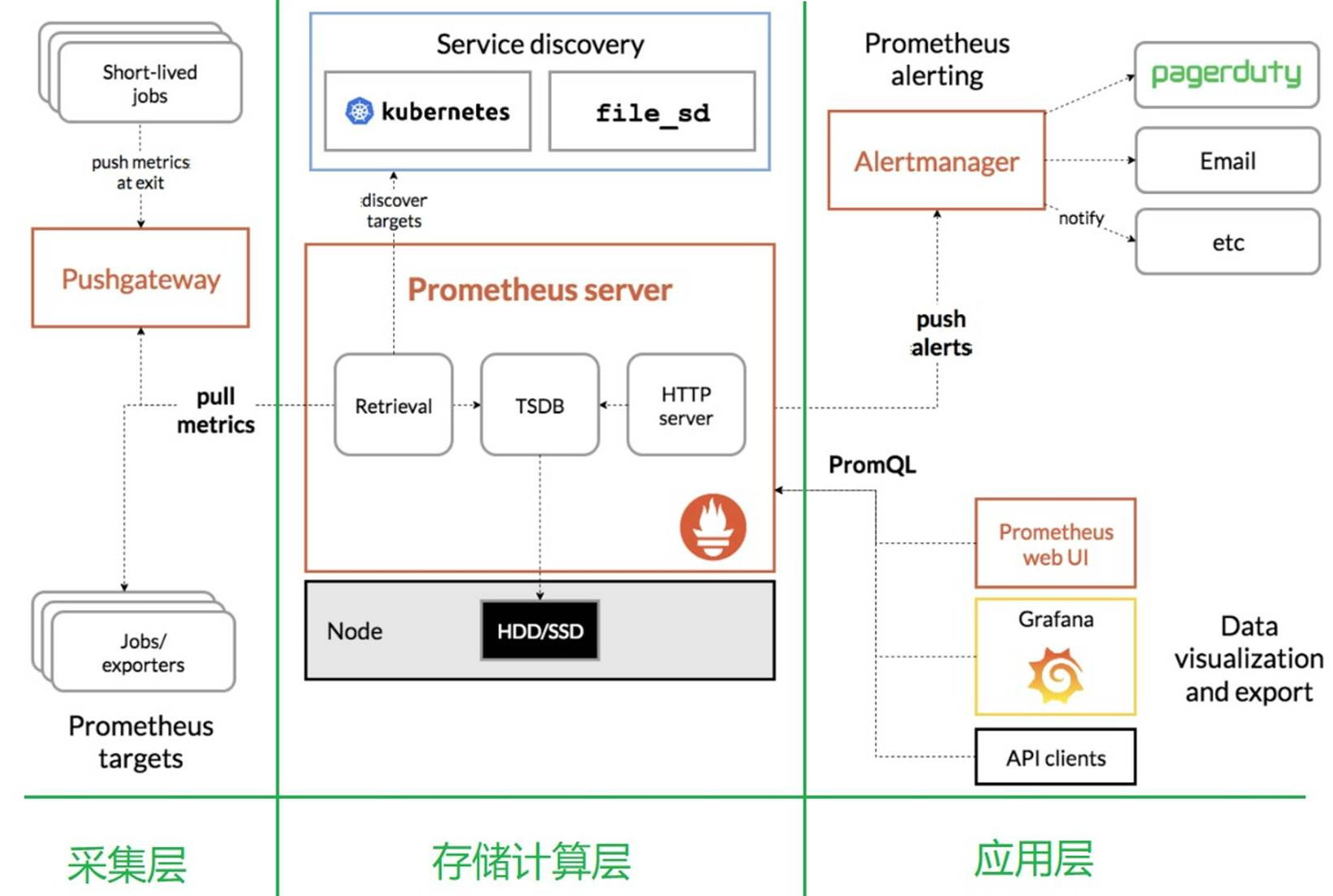
可以说,kubernetes是整个Golang生态最成功的的项目,没有之一,而Golang之所以能发展如此之好,很大程度也是乘着云原生的东风,docker + k8s,尤其是k8s,这两个项目都是Golang实现的,且是开源的,Golang有天然优势!
Kubernetes Github地址:https://github.com/kubernetes/kubernetes
顺便附上docker的源码地址:https://github.com/docker/docker-ce
我本系列选择的k8s版本为:release-1.19,重在理解过程,之后的版本虽然有细微的变动,但是整体结构和框架是不变的!
一、前置条件
1、熟悉Golang这门语言
-
语言基础
-
go modules模块化
2、对 k8s 的使用得比较熟悉,最好还要熟悉并理解:
-
k8s的基础架构:master – worker 模式
-
master决定worker里面有什么?
-
worker只是和master(api)通讯;每个节点自己干自己的活;
-
相关组件:
-
Master节点:
-
controller-manager:控制器管理器,管理着每一个控制器,控制器又可以成为工作负载:https://kubernetes.io/zh/docs/concepts/workloads/controllers/
会根据具体的控制器(如Deployment,ReplicaSet),生成对应的Pod信息(但是具体在哪台机器上部署,不由cm决定);
-
api-Server:整个k8s集群对内对外通讯的核心;
-
etcd:键值数据库(有点像redis,也是Go实现的);
-
scheduler:监听到新的Pod信息,根据计算,决定哪些节点适合部署这些Pod;
-
Worker节点:
-
kubelet:每一个node节点上必须安装的组件,随时和Master节点保持联系,看看有没有自己的活要干;以及当前Node节点上应用容器的启停!
-
在Worker节点:监工,指挥别人干活;
-
在Master节点:master的小助手,活不用master干,而是由小助手帮忙干!
-
kube-proxy:代理,代理网络
-
pod应用:由上面kubelet启动的容器成为Pod,Pod是K8s的基本单位!
-
工作流程: 一个简单的 kubectl create -f mydeploy.yml 命令是如何在k8s的各个组件间流转的!
以上所有的内容,都可以在我很久前的一篇文章中得到答案:Kubernetes的基础与安装
3、如果还能提前了解一下以下技术栈就更好了(我专门另起了文章讲解这些技术栈):
-
Cobra:Go语言实现的强大的命令行框架:Go 语言强大的命令行框架 Cobra 详解
-
Pflag:Go 语言命令行解析增强工具包:Go 语言命令行解析增强工具包-pflag
-
Viper:Go语言功能齐全的配置管理库:Go语言功能齐全的配置管理库-Viper
-
Visitor:Go语言中常见的访问者模式的实现:可以参考阅读(外链):k8s Visitor 模式
-
协助理解:需要被访问的Visitor类中定义一个Visit方法,而方法的参数是一个func,大概代码如下:
// pkg\resource\interfaces.go
type VisitorFunc func(*Info, error) error
type Visitor interface {
Visit(VisitorFunc) error
}
// 数据在我这,但是你打算怎么处理我不知道,你直接传个方法进来吧(#^.^#)
// 是不是很像Java中的lambda表达式,或者函数式接口?
二、开始阅读源码(release-1.19)
我们将跟随一个简单的命令,一点一点开始我们的 k8s 核心源码阅读之路:
kubectl create -f mydeployment.yaml
1、首先我们需要找到 kubectl 命令的如下:
它就位于 ./cmd/kubectl/kubectl.go 这个文件中:
package main
import (
goflag "flag"
"math/rand"
"os"
"time"
"github.com/spf13/pflag"
cliflag "k8s.io/component-base/cli/flag"
"k8s.io/kubectl/pkg/util/logs"
"k8s.io/kubernetes/pkg/kubectl/cmd"
// Import to initialize client auth plugins.
_ "k8s.io/client-go/plugin/pkg/client/auth"
)
func main() {
// Seed即随机的种子,每次用时间戳作为种子,才能保证每一次的随机结果是不一样的
rand.Seed(time.Now().UnixNano())
// 以默认参数创建得到kubectl命令树
// kubernetes的所有组件入口函数几乎都是一致的
// 这也将是我们要重点跟踪的方法
command := cmd.NewDefaultKubectlCommand()
// 设置NormalizeFunc函数,为标识起规范的别名(_转成-)
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
pflag.CommandLine.AddGoFlagSet(goflag.CommandLine) // 目的是兼容用原生flag库创建的标识
// 日志的初始化与defer退出(非核心,后面都不会深入跟踪)
logs.InitLogs()
defer logs.FlushLogs()
// Cobra框架的标准写法
// pflag.Parse() 工作也是在这里面完成的,已经被Cobra封装好了
if err := command.Execute(); err != nil {
os.Exit(1)
}
}
几乎所有的k8s组件程序入口都会先调用一次 rand.Seed():
我们可以通过以下代码做个简单的测试:
func main() {
rand.Seed(time.Now().UnixNano()) // 如果不加这行代码,程序的每次输出都是相同的值
num := rand.Intn(10)
fmt.Println("num =", num)
}
2、NewDefaultKubectlCommand()方法:
// NewDefaultPluginHandler(plugin.ValidPluginFilenamePrefixes): 创建一个默认的插件处理程序
// os.Args: 命令行参数切片,os.Args[0]是程序名称,os.Args[1:]就是后面的命令、标识、参数等字符串
// os.Stdin: 标准输入
// os.Stdout: 标准输出
// os.Stderr: 标准错误输出
func NewDefaultKubectlCommand() *cobra.Command {
return NewDefaultKubectlCommandWithArgs(NewDefaultPluginHandler(plugin.ValidPluginFilenamePrefixes), os.Args, os.Stdin, os.Stdout, os.Stderr)
}
其中关于默认的插件处理handler:接收了一个校验前缀,默认值为kubectl,即:如果我们的命令为 kubectl abc ,则会去寻找一个叫作 kubectl-abc 的插件!
但是我个人工作中,其实是很少使用插件的;
关于怎么判断命令行中的参数,到底是子命令,还是插件名呢?我后续也会讲!
3、NewDefaultKubectlCommandWithArgs():
func NewDefaultKubectlCommandWithArgs(pluginHandler PluginHandler, args []string, in io.Reader, out, errout io.Writer) *cobra.Command {
// 传入标准输入、输出、错误输出,新建并初始化等到 Cobra 的命令树
cmd := NewKubectlCommand(in, out, errout) // 需要重点跟踪的方法
// 如果调用这个方法时,并没有传入插件handler,那么就可以直接将上面New到的cmd返回出去了
if pluginHandler == nil {
return cmd
}
// 根据源码追踪,我们这个场景下,肯定是转了pluginHandler的,那么判断args是否大于1
// kubectl == 1,那说明就是空命令 kubectl
if len(args) > 1 {
// 根据我们假定的命令,那这里得到的 cmdPathPieces = create -f mydeployment.yaml
cmdPathPieces := args[1:]
// cmd.Find(cmdPathPieces):作用是尝试去找指定的子命令
// 如果能找到 err = nil,不用做啥事,把cmd返回出去,main函数中的command.Execute()会执行到具体的子命令(Cobra框架)
// 如果没找到 err != nil
if _, _, err := cmd.Find(cmdPathPieces); err != nil {
// 在子命令中没有找到对应的子命令,那么再尝试让插件处理器处理看看
// 如果插件执行也报错了,那么说明当前命令不合法,打印错误,程序退出
if err := HandlePluginCommand(pluginHandler, cmdPathPieces); err != nil {
fmt.Fprintf(errout, "%v\n", err)
os.Exit(1)
}
}
}
return cmd // 能走到这里,说明当前执行的cmd是一个合法的cmd
}
4、构建command命令树的核心方法:NewKubectlCommand() — 很长
这一段主要是看根命令rootCmd是如何被构建?
还有将命令行标识参数是如何被转换成一些配置类,或全局标识,传递给后面的子命令中的?
func NewKubectlCommand(in io.Reader, out, err io.Writer) *cobra.Command {
// 见名知意:对warning的处理器,非核心,不追踪
warningHandler := rest.NewWarningWriter(err, rest.WarningWriterOptions{Deduplicate: true, Color: term.AllowsColorOutput(err)})
warningsAsErrors := false // 是否需要将warning以error的方式抛出去,取决于命令行参数warnings-as-errors
// 这里创建主命令rootCmd,其他的子命令将会挂载在它上面
// 标准Cobra写法,很多字段不用解释
cmds := &cobra.Command{
Use: "kubectl",
Short: i18n.T("kubectl controls the Kubernetes cluster manager"),
Long: templates.LongDesc(`
kubectl controls the Kubernetes cluster manager.
Find more information at:
https://kubernetes.io/docs/reference/kubectl/overview/`),
// help命令(*cobra.Command.Help())
Run: runHelp,
// 五大<Hooks>E第一,对子命令也生效
PersistentPreRunE: func(*cobra.Command, []string) error {
rest.SetDefaultWarningHandler(warningHandler)
// 这里是做pprof性能分析,跳转到对应代码可以看到,我们可以用参数 --profile xxx 来采集性能指标,默认保存在当前目录下的profile.pprof中
// 注:pprof是Go官方提供的性能分析工具,可以分析程序的运行情况,并且提供可视化的功能
return initProfiling()
},
// 五大<Hooks>E最后,对子命令也生效
PersistentPostRunE: func(*cobra.Command, []string) error {
// 保存pprof性能分析指标
if err := flushProfiling(); err != nil {
return err
}
// 打印warning条数
if warningsAsErrors {
count := warningHandler.WarningCount()
switch count {
case 0:
// no warnings
case 1:
return fmt.Errorf("%d warning received", count)
default:
return fmt.Errorf("%d warnings received", count)
}
}
return nil
},
// bash自动补齐功能,可通过 kubectl completion bash 命令查看(我在Cobra详解中重点讲过)
BashCompletionFunction: bashCompletionFunc,
}
flags := cmds.PersistentFlags() // 之后通过此flags定义的标识,将都是全局标识
flags.SetNormalizeFunc(cliflag.WarnWordSepNormalizeFunc) // 对参数中的“_”进行warn提醒,貌似
flags.SetNormalizeFunc(cliflag.WordSepNormalizeFunc) // 貌似与main函数中的这段代码重复了
// 为kubectl添加默认的性能测算参数,默认是关闭的
// 如果在参数中设置为开启,则会进行测算,具体可见命令调用前后的回调
addProfilingFlags(flags)
// 从命令中获取warnings-as-errors变量,赋值给warningsAsErrors变量,默认值为 warningsAsErrors := false
flags.BoolVar(&warningsAsErrors, "warnings-as-errors", warningsAsErrors, "Treat warnings received from the server as errors and exit with a non-zero exit code")
// ConfigFlags对象, 后续创建rest client的生成基本来自这(留意一下)
kubeConfigFlags := genericclioptions.NewConfigFlags(true).WithDeprecatedPasswordFlag()
// 设置命令参数,将参数解析值绑定到kubeConfigFlags
kubeConfigFlags.AddFlags(flags) // 从flags中解析标识参数,赋值给ConfigFlags中的对应属性,后面要用
// 包装一层,是一个代理,其实差不多就是加一个是否匹配client与server版本的参数match-server-version
matchVersionKubeConfigFlags := cmdutil.NewMatchVersionFlags(kubeConfigFlags)
matchVersionKubeConfigFlags.AddFlags(cmds.PersistentFlags())
// 还是为了兼容原生Flag标识
cmds.PersistentFlags().AddGoFlagSet(flag.CommandLine)
// 最终kubeconfig对象被包装成一个工厂类型
// 该对象实现了DynamicClient(), KubernetesClientSet(), NewBuilder()等接口
// 这一层层的包装是委托者设计模式 + 工厂模式,见下文
f := cmdutil.NewFactory(matchVersionKubeConfigFlags)
// 国际化
i18n.LoadTranslations("kubectl", nil)
// 还是规范化标识
cmds.SetGlobalNormalizationFunc(cliflag.WarnWordSepNormalizeFunc)
// 将标准输入,输出,错误包装一下
ioStreams := genericclioptions.IOStreams{In: in, Out: out, ErrOut: err}
// kubectl定义了7大组命令,结合Message和各个子命令的package名来看;
// 这里才是各个常用的子命令的入口,我们待会重点从这里往下看
groups := templates.CommandGroups{
// 常规的子命令分组包装
}
// 将上面groups中的子命令全部挂载到rootCmd上
groups.Add(cmds) // 这句话要反着理解,其实是遍历group中的command,然后调用 cmds.AddCommand()
filters := []string{"options"}
// alpha相关的子命令
// Hide the "alpha" subcommand if there are no alpha commands in this build.
alpha := cmdpkg.NewCmdAlpha(f, ioStreams)
if !alpha.HasSubCommands() {
filters = append(filters, alpha.Name())
}
templates.ActsAsRootCommand(cmds, filters, groups...)
// 代码补全相关
for name, completion := range bashCompletionFlags {
if cmds.Flag(name) != nil {
if cmds.Flag(name).Annotations == nil {
cmds.Flag(name).Annotations = map[string][]string{}
}
cmds.Flag(name).Annotations[cobra.BashCompCustom] = append(
cmds.Flag(name).Annotations[cobra.BashCompCustom],
completion,
)
}
}
// 添加其余子命令,包括 alpha/config/plugin/version/api-versions/api-resources/options
cmds.AddCommand(alpha) // 之后的版本好像没有alpha了
cmds.AddCommand(cmdconfig.NewCmdConfig(f, clientcmd.NewDefaultPathOptions(), ioStreams))
cmds.AddCommand(plugin.NewCmdPlugin(f, ioStreams))
cmds.AddCommand(version.NewCmdVersion(f, ioStreams))
cmds.AddCommand(apiresources.NewCmdAPIVersions(f, ioStreams))
cmds.AddCommand(apiresources.NewCmdAPIResources(f, ioStreams))
cmds.AddCommand(options.NewCmdOptions(ioStreams.Out))
return cmds
}
5、groups := templates.CommandGroups{} 对子命令进行分组管理:
groups := templates.CommandGroups{
{
// 1. 初级命令,包括 create/expose/run/set
Message: "Basic Commands (Beginner):",
Commands: []*cobra.Command{
create.NewCmdCreate(f, ioStreams), // 我将对create命令进行详细跟踪
expose.NewCmdExposeService(f, ioStreams),
run.NewCmdRun(f, ioStreams),
set.NewCmdSet(f, ioStreams),
},
},
{
// 2. 初中级命令,包括explain/get/edit/delete
Message: "Basic Commands (Intermediate):",
Commands: []*cobra.Command{
explain.NewCmdExplain("kubectl", f, ioStreams),
get.NewCmdGet("kubectl", f, ioStreams),
edit.NewCmdEdit(f, ioStreams),
delete.NewCmdDelete(f, ioStreams),
},
},
{
// 3. 部署命令,包括 rollout/scale/autoscale
Message: "Deploy Commands:",
Commands: []*cobra.Command{
rollout.NewCmdRollout(f, ioStreams),
scale.NewCmdScale(f, ioStreams),
autoscale.NewCmdAutoscale(f, ioStreams),
},
},
{
// 4. 集群管理命令,包括 cerfificate/cluster-info/top/cordon/drain/taint
Message: "Cluster Management Commands:",
Commands: []*cobra.Command{
certificates.NewCmdCertificate(f, ioStreams),
clusterinfo.NewCmdClusterInfo(f, ioStreams),
top.NewCmdTop(f, ioStreams),
drain.NewCmdCordon(f, ioStreams),
drain.NewCmdUncordon(f, ioStreams),
drain.NewCmdDrain(f, ioStreams),
taint.NewCmdTaint(f, ioStreams),
},
},
{
// 5. 故障排查和调试,包括 describe/logs/attach/exec/port-forward/proxy/cp/auth
Message: "Troubleshooting and Debugging Commands:",
Commands: []*cobra.Command{
describe.NewCmdDescribe("kubectl", f, ioStreams),
logs.NewCmdLogs(f, ioStreams),
attach.NewCmdAttach(f, ioStreams),
cmdexec.NewCmdExec(f, ioStreams),
portforward.NewCmdPortForward(f, ioStreams),
proxy.NewCmdProxy(f, ioStreams),
cp.NewCmdCp(f, ioStreams),
auth.NewCmdAuth(f, ioStreams),
},
},
{
// 6. 高级命令,包括diff/apply/patch/replace/wait/convert/kustomize
Message: "Advanced Commands:",
Commands: []*cobra.Command{
diff.NewCmdDiff(f, ioStreams),
apply.NewCmdApply("kubectl", f, ioStreams),
patch.NewCmdPatch(f, ioStreams),
replace.NewCmdReplace(f, ioStreams),
wait.NewCmdWait(f, ioStreams),
convert.NewCmdConvert(f, ioStreams),
kustomize.NewCmdKustomize(ioStreams),
},
},
{
// 7. 设置命令,包括label,annotate,completion
Message: "Settings Commands:",
Commands: []*cobra.Command{
label.NewCmdLabel(f, ioStreams),
annotate.NewCmdAnnotate("kubectl", f, ioStreams),
completion.NewCmdCompletion(ioStreams.Out, ""),
},
},
}
6、create 子命令的核心创建方法 NewCmdCreate():
func NewCmdCreate(f cmdutil.Factory, ioStreams genericclioptions.IOStreams) *cobra.Command {
// create子命令的相关配置封装对象(后面获取到的Flag标识的值,几乎都是封装在这个o对象中传递的)
o := NewCreateOptions(ioStreams)
// create子命令的主命令
cmd := &cobra.Command{
Use: "create -f FILENAME",
DisableFlagsInUseLine: true,
Short: i18n.T("Create a resource from a file or from stdin."),
Long: createLong,
Example: createExample,
// create 主命令的执行体
Run: func(cmd *cobra.Command, args []string) {
// 如果文件切片是空的
if cmdutil.IsFilenameSliceEmpty(o.FilenameOptions.Filenames, o.FilenameOptions.Kustomize) {
ioStreams.ErrOut.Write([]byte("Error: must specify one of -f and -k\n\n"))
defaultRunFunc := cmdutil.DefaultSubCommandRun(ioStreams.ErrOut)
defaultRunFunc(cmd, args)
return
}
cmdutil.CheckErr(o.Complete(f, cmd))
cmdutil.CheckErr(o.ValidateArgs(cmd, args))
// 最终:核心的运行代码逻辑是在这里的RunCreate,需要重点跟踪
cmdutil.CheckErr(o.RunCreate(f, cmd))
},
}
// o.RecordFlags 当前还是空的 = genericclioptions.NewRecordFlags()
// 从 kubectl create --record=false 中获取record值,赋值给 o.RecordFlags.Record 这个标识
o.RecordFlags.AddFlags(cmd)
usage := "to use to create the resource"
// 从 kubectl create -f mydeployment.yml 中获取值f值/kustomize值/recursive值,保存到o.FilenameOptions对象中
// 运行主题中开始就判断filename是否为空,就是在这里赋的值
cmdutil.AddFilenameOptionFlags(cmd, &o.FilenameOptions, usage)
// 直接获取了validate标识的值,备用,需要时再取用:cmdutil.GetFlagBool(cmd, "validate")
cmdutil.AddValidateFlags(cmd)
// 以下也都是一些对标识的取值赋值操作
cmd.Flags().BoolVar(&o.EditBeforeCreate, "edit", o.EditBeforeCreate, "Edit the API resource before creating")
cmd.Flags().Bool("windows-line-endings", runtime.GOOS == "windows",
"Only relevant if --edit=true. Defaults to the line ending native to your platform.")
cmdutil.AddApplyAnnotationFlags(cmd)
cmdutil.AddDryRunFlag(cmd)
cmd.Flags().StringVarP(&o.Selector, "selector", "l", o.Selector, "Selector (label query) to filter on, supports '=', '==', and '!='.(e.g. -l key1=value1,key2=value2)")
cmd.Flags().StringVar(&o.Raw, "raw", o.Raw, "Raw URI to POST to the server. Uses the transport specified by the kubeconfig file.")
cmdutil.AddFieldManagerFlagVar(cmd, &o.fieldManager, "kubectl-create")
o.PrintFlags.AddFlags(cmd)
// create命令下的子命令,如 kubectl create namespace/role等
cmd.AddCommand(NewCmdCreateNamespace(f, ioStreams))
cmd.AddCommand(NewCmdCreateQuota(f, ioStreams))
cmd.AddCommand(NewCmdCreateSecret(f, ioStreams))
cmd.AddCommand(NewCmdCreateConfigMap(f, ioStreams))
cmd.AddCommand(NewCmdCreateServiceAccount(f, ioStreams))
cmd.AddCommand(NewCmdCreateService(f, ioStreams))
cmd.AddCommand(NewCmdCreateDeployment(f, ioStreams))
cmd.AddCommand(NewCmdCreateClusterRole(f, ioStreams))
cmd.AddCommand(NewCmdCreateClusterRoleBinding(f, ioStreams))
cmd.AddCommand(NewCmdCreateRole(f, ioStreams))
cmd.AddCommand(NewCmdCreateRoleBinding(f, ioStreams))
cmd.AddCommand(NewCmdCreatePodDisruptionBudget(f, ioStreams))
cmd.AddCommand(NewCmdCreatePriorityClass(f, ioStreams))
cmd.AddCommand(NewCmdCreateJob(f, ioStreams))
cmd.AddCommand(NewCmdCreateCronJob(f, ioStreams))
return cmd
}
7、create 子命令的最终运行方法RunCreate():
想看懂这里的逻辑,需要我们对Visitor访问者模式有着一定深度的了解,不然看着会很别扭!
验证或不常用的标识走的分支我们就不深入跟踪了,还是重点跟踪主逻辑:
kubectl create -f mydeployment
另外,我这里只单独大概讲解 RunCreate() 方法体本身,关于其中的很多代码细节跟踪,我单独开一个章节跟踪讲解;不然这个章节内容太多了,阅读起来费劲!
/**
o *CreateOptions: createCmd命令执行的参数包装
f cmdutil.Factory:传入的Factory,是对kubeconfig对象的包装,实现了DynamicClient(), KubernetesClientSet(), NewBuilder()等接口;
—— 里面封装了一个很重要的对象,就是 与kube-apiserver交互客户端RESTClient客户端
cmd *cobra.Command:就是我们的createCmd命令
*/
func (o *CreateOptions) RunCreate(f cmdutil.Factory, cmd *cobra.Command) error {
// 我们假定的命令,使用本地file文件的,所以这个raw就不深入跟踪了
if len(o.Raw) > 0 {
restClient, err := f.RESTClient()
if err != nil {
return err
}
return rawhttp.RawPost(restClient, o.IOStreams, o.Raw, o.FilenameOptions.Filenames[0])
}
// --edit=true的场景
if o.EditBeforeCreate {
return RunEditOnCreate(f, o.PrintFlags, o.RecordFlags, o.IOStreams, cmd, &o.FilenameOptions, o.fieldManager)
}
// 验证分支,都不是咱们跟踪的核心
schema, err := f.Validator(cmdutil.GetFlagBool(cmd, "validate"))
if err != nil {
return err
}
cmdNamespace, enforceNamespace, err := f.ToRawKubeConfigLoader().Namespace()
if err != nil {
return err
}
// 实例化Builder,这块的逻辑比较复杂,我们先关注文件部分
// 下方匿名函数中:info来源就是这里的Builder,前面部分都是将Builder参数化,核心的生成为Do函数
r := f.NewBuilder().
Unstructured(). // 这里会在b.mapper中获得并包装一个RESTClient,b.getClient
Schema(schema).
ContinueOnError().
NamespaceParam(cmdNamespace).DefaultNamespace().
// 读取文件信息,发现除了支持简单的本地文件,也支持标准输入和http/https协议访问的文件,保存为Visitor
FilenameParam(enforceNamespace, &o.FilenameOptions). // 如何确定我们真正的Visitor实现具体是哪个呢?(下一章节单独跟踪讲解)
LabelSelectorParam(o.Selector).
Flatten().
Do()
err = r.Err()
if err != nil {
return err
}
count := 0
// 调用visit()函数,创建资源,从传入参数来看,数据来源于Info这个结构
// 如何确定我们整的的Visitor实现具体是哪个呢?猜的话应该是FileVisitor,详看上面FilenameParam()方法的跟踪
// r就是数据存放的地方,Visit(func()error{})中的方法,就是通过传进来的func函数,处理r中的Info属性(下一章节单独跟踪讲解)
err = r.Visit(func(info *resource.Info, err error) error {
if err != nil {
return err
}
if err := util.CreateOrUpdateAnnotation(cmdutil.GetFlagBool(cmd, cmdutil.ApplyAnnotationsFlag), info.Object, scheme.DefaultJSONEncoder()); err != nil {
return cmdutil.AddSourceToErr("creating", info.Source, err)
}
if err := o.Recorder.Record(info.Object); err != nil {
klog.V(4).Infof("error recording current command: %v", err)
}
if o.DryRunStrategy != cmdutil.DryRunClient {
if o.DryRunStrategy == cmdutil.DryRunServer {
if err := o.DryRunVerifier.HasSupport(info.Mapping.GroupVersionKind); err != nil {
return cmdutil.AddSourceToErr("creating", info.Source, err)
}
}
// Helper 提供了检索或更改 RESTful 资源的方法,可以理解为是个工具类
obj, err := resource.
NewHelper(info.Client, info.Mapping). // 从info中获得RestClient,赋值给Helper对象
DryRun(o.DryRunStrategy == cmdutil.DryRunServer).
WithFieldManager(o.fieldManager).
Create(info.Namespace, true, info.Object) // 最终会调用 *Helper.createResource(m.RESTClient, m.Resource, namespace, obj, options)
if err != nil {
return cmdutil.AddSourceToErr("creating", info.Source, err)
}
info.Refresh(obj, true)
}
count++
// 打印结果 xxxx created
return o.PrintObj(info.Object)
})
if err != nil {
return err
}
if count == 0 {
return fmt.Errorf("no objects passed to create")
}
return nil
}
当前章节内容太多了,所以新开一个章节,跟踪Visitor模式,以及最终通过RestClient向api-server发送命令的逻辑;
三、RunCreate()方法中的Vistor模式跟踪 — 理清 info 的来龙去脉
1、r.Visit(func(info *resource.Info, err error) error {}中的info数据是哪儿来的?
首先进入:
func (r *Result) Visit(fn VisitorFunc) error {
if r.err != nil {
return r.err
}
// 这里的r.visitor是FileVisitor,本章节后面讲
err := r.visitor.Visit(fn)
return utilerrors.FilterOut(err, r.ignoreErrors...)
}
再跟踪 FileVisitor.Visit() 方法:
func (v *FileVisitor) Visit(fn VisitorFunc) error {
var f *os.File
// 我们的v.Path是由filename转化为的FileVisitor,不是constSTDINstr,所以会进入else分支
if v.Path == constSTDINstr {
f = os.Stdin
} else {
var err error
f, err = os.Open(v.Path)
if err != nil {
return err
}
defer f.Close()
}
// TODO: Consider adding a flag to force to UTF16, apparently some
// Windows tools don't write the BOM
utf16bom := unicode.BOMOverride(unicode.UTF8.NewDecoder())
v.StreamVisitor.Reader = transform.NewReader(f, utf16bom)
// 读取文件,将FileVisitor转化为StreamVisitor后,调用这个,参数就是我们最外层的func(){}方法
return v.StreamVisitor.Visit(fn)
}
这时候我么就是继续跟踪StreamVisitor.Visit()方法了:
func (v *StreamVisitor) Visit(fn VisitorFunc) error {
d := yaml.NewYAMLOrJSONDecoder(v.Reader, 4096)
for {
// 因为实在StreamVisitor中,会将流数据存入到runtime.RawExtension{},从而赋值给ext变量
// 这对我们非常重要,算是我们真正从mydeployment.yaml文件中读到的原始数据
// 其中的ext.Raw就是[]byte原始数据字节数组
ext := runtime.RawExtension{}
// 首先看是否能够正常解码
if err := d.Decode(&ext); err != nil {
if err == io.EOF {
return nil
}
return fmt.Errorf("error parsing %s: %v", v.Source, err)
}
// TODO: This needs to be able to handle object in other encodings and schemas.
ext.Raw = bytes.TrimSpace(ext.Raw)
if len(ext.Raw) == 0 || bytes.Equal(ext.Raw, []byte("null")) {
continue
}
// 再验证看看Schema结构是否正确
if err := ValidateSchema(ext.Raw, v.Schema); err != nil {
return fmt.Errorf("error validating %q: %v", v.Source, err)
}
// 这个方法将是最重要的方法,因为它将得到我们func(){}最需要的info,然后最终调用func(){}
// 我们将重点跟踪这个方法,看看它是如何给info对象赋值的
info, err := v.infoForData(ext.Raw, v.Source)
if err != nil {
if fnErr := fn(info, err); fnErr != nil {
return fnErr
}
continue
}
if err := fn(info, nil); err != nil {
return err
}
}
}
我们将会发现,在func(){}中需要从info中获取的数据,都将在v.infoForData()方法中被赋值:
/** 在func(){}中需要从info中获取的参数如下:
info.Object:
info.Source:
info.Mapping:
info.Client:
info.Namespace:
*/
func (m *mapper) infoForData(data []byte, source string) (*Info, error) {
// 通过m.decoder,从 mydeployment.yaml 文件读取流中 解析出 Obj对象,以及gvk类型(Group Version Kind信息)
// Obj对象可以是我们的 Pod/Deployment/Service 等各类资源
obj, gvk, err := m.decoder.Decode(data, nil, nil)
if err != nil {
return nil, fmt.Errorf("unable to decode %q: %v", source, err)
}
name, _ := metadataAccessor.Name(obj)
namespace, _ := metadataAccessor.Namespace(obj)
resourceVersion, _ := metadataAccessor.ResourceVersion(obj)
ret := &Info{
Source: source,
Namespace: namespace,
Name: name,
ResourceVersion: resourceVersion,
Object: obj,
}
if m.localFn == nil || !m.localFn() {
restMapper, err := m.restMapperFn()
if err != nil {
return nil, err
}
mapping, err := restMapper.RESTMapping(gvk.GroupKind(), gvk.Version)
if err != nil {
return nil, fmt.Errorf("unable to recognize %q: %v", source, err)
}
ret.Mapping = mapping
// 在f.NewBuilder().Unstructured() 时,定义了b.mapper.clientFn = b.getClient
// 所以这里才可以直接调用执行:得到最终需要的RestClient
client, err := m.clientFn(gvk.GroupVersion())
if err != nil {
return nil, fmt.Errorf("unable to connect to a server to handle %q: %v", mapping.Resource, err)
}
ret.Client = client
}
return ret, nil
}
现在我们算是把Visitor的主干理清了,知道了 r.Visit(func(info *resource.Info, err error) 这个访问者模式,是如何从r中获得info信息,从而调用 func() 方法的了!
下面,我们将把info赋值截断的一些重点分支,扒出来跟踪一下。
r.visitor为什么就是FileVisitor?
m.decoder.Decode() 中的decoder解码器是谁?啥时候设置的?返回结果是啥?
m.clientFn(gvk.GroupVersion()) 中的clientFn是啥,啥时候设置的?
m.restMapperFn()什么时候设置的,info.Mapping中到底存放的是什么?
2、r.visitor为什么就是FileVisitor?
首先我们快速定位下入口位置,肯定是在 r 被 build 期间设置的,见名知意,就是这个位置:
r := f.NewBuilder(). ... FilenameParam(enforceNamespace, &o.FilenameOptions). ... Do()
进入FilenameParam()方法,重点确定我们将要进入的分支,以及是在哪儿将文件path转化为FileVisitor的
func (b *Builder) FilenameParam(enforceNamespace bool, filenameOptions *FilenameOptions) *Builder {
if errs := filenameOptions.validate(); len(errs) > 0 {
b.errs = append(b.errs, errs...)
return b
}
recursive := filenameOptions.Recursive
paths := filenameOptions.Filenames // 根据场景,我们的filenames = mydeployment.yaml
for _, s := range paths {
switch {
case s == "-":
// 如果是 -,就是用标准的Stdin, 其中就是使用的FileVisitor
b.Stdin()
case strings.Index(s, "http://") == 0 || strings.Index(s, "https://") == 0:
// 如果有http或者https则就是用URLVisitor
url, err := url.Parse(s)
if err != nil {
b.errs = append(b.errs, fmt.Errorf("the URL passed to filename %q is not valid: %v", s, err))
continue
}
b.URL(defaultHttpGetAttempts, url)
default: // 所以走的肯定是这个分支
if !recursive {
b.singleItemImplied = true
}
b.Path(recursive, s) // 将文件path转化为对应的FileVisitor
}
}
if filenameOptions.Kustomize != "" {
b.paths = append(b.paths, &KustomizeVisitor{filenameOptions.Kustomize,
NewStreamVisitor(nil, b.mapper, filenameOptions.Kustomize, b.schema)})
}
if enforceNamespace {
b.RequireNamespace()
}
return b
}
继续跟踪 b.Path(recursive, s) 方法,重点还是看在何处将原path路径转化为FileVisitor的:
func (b *Builder) Path(recursive bool, paths ...string) *Builder {
for _, p := range paths {
_, err := os.Stat(p)
if os.IsNotExist(err) {
b.errs = append(b.errs, fmt.Errorf("the path %q does not exist", p))
continue
}
if err != nil {
b.errs = append(b.errs, fmt.Errorf("the path %q cannot be accessed: %v", p, err))
continue
}
// 将文件path路径,转化为FileVisitor,内部也简单,就是对文件进行访问,然后封装一个StreamVisitor对文件进行流读取
visitors, err := ExpandPathsToFileVisitors(b.mapper, p, recursive, FileExtensions, b.schema)
if err != nil {
b.errs = append(b.errs, fmt.Errorf("error reading %q: %v", p, err))
}
if len(visitors) > 1 {
b.dir = true
}
// 我们按只有一个文件来看,原来的b.paths是空的,visitors是被包装过的FileVisitor
b.paths = append(b.paths, visitors...)
}
if len(b.paths) == 0 && len(b.errs) == 0 {
b.errs = append(b.errs, fmt.Errorf("error reading %v: recognized file extensions are %v", paths, FileExtensions))
}
return b
}
在跟踪 ExpandPathsToFileVisitors() 方法,就一目了然了:
func ExpandPathsToFileVisitors(mapper *mapper, paths string, recursive bool,
extensions []string, schema ContentValidator) ([]Visitor, error) {
var visitors []Visitor
// 根据path路径,读取文件内存
err := filepath.Walk(paths, func(path string, fi os.FileInfo, err error) error {
if err != nil {
return err
}
// 必须是文件,不可以是文件夹
if fi.IsDir() {
if path != paths && !recursive {
return filepath.SkipDir
}
return nil
}
if path != paths && ignoreFile(path, extensions) {
return nil
}
// 不仅确定了是FileVisitor,还知道了FileVisitor的组成
visitor := &FileVisitor{
Path: path,
StreamVisitor: NewStreamVisitor(nil, mapper, path, schema),
}
visitors = append(visitors, visitor)
return nil
})
if err != nil {
return nil, err
}
return visitors, nil
}
到这里,我们的结论已经非常清晰了,在当前假定场景下:
r 中的Visitor就是FileVisitor,是对 mydeployment.yaml 文件的文件访问器;
FileVisitor中封装的是path路径信息 + 一个StreamVisitor流读取器,这也是我们跟踪 r.Visit() 方法时,最终为什么进入的是StreamVisitor内部,忘记的,可以回去看上面的代码!
3、m.decoder.Decode() 中的decoder解码器是谁?啥时候设置的?返回结果是啥?
其实后面几个疑点的入口都是在 Unstructured() 方法中:
r := f.NewBuilder(). Unstructured(). ...
可以看到,对我们关心的 restMapperFn、clientFn、decoder,都进行了赋值:
func (b *Builder) Unstructured() *Builder {
if b.mapper != nil {
b.errs = append(b.errs, fmt.Errorf("another mapper was already selected, cannot use unstructured types"))
return b
}
b.objectTyper = unstructuredscheme.NewUnstructuredObjectTyper()
b.mapper = &mapper{
localFn: b.isLocal,
restMapperFn: b.restMapperFn, // 这里为resrMapperFn进行了赋值,根据命名,我们也能知道,这是一个方法;
clientFn: b.getClient, // 为clientFn进行了,赋值,根据命令我们也能知道,这是一个方法,需要被调用时,才会返回具体的Client对象
decoder: &metadataValidatingDecoder{unstructured.UnstructuredJSONScheme}, // 这里为decoder进行了赋值
}
return b
}
我们就先来看看decoder到底是个啥?
decoder: &metadataValidatingDecoder{unstructured.UnstructuredJSONScheme}
// 首先这是一个metadataValidatingDecoder
// 是对内部解码器decoder的一个包装类,同时进行了功能增强:确保元数据的schema字段在返回前被解码
type metadataValidatingDecoder struct {
decoder runtime.Decoder
}
// 我们重点还是看它内部包装的那个编解码器:
unstructured.UnstructuredJSONScheme
// Encode:可以将json数据编码成非结构化的数据;
// Decode:可以将非结构化的数据,解码成json数据;
当我们在 infoForData() 方法中使用时,就是使用的他的Decode解码功能,将[]byte形式的data数据,解析为Obj对象:
func (s unstructuredJSONScheme) Decode(data []byte, _ *schema.GroupVersionKind, obj runtime.Object)
(runtime.Object, *schema.GroupVersionKind, error) {
var err error
if obj != nil {
// 如果obj有值,则代表将decode解码后的数据写到obj中
err = s.decodeInto(data, obj)
} else {
// 如果obj为空,则代表直接解码,然后返回
obj, err = s.decode(data)
}
if err != nil {
return nil, nil, err
}
gvk := obj.GetObjectKind().GroupVersionKind()
if len(gvk.Kind) == 0 {
return nil, &gvk, runtime.NewMissingKindErr(string(data))
}
return obj, &gvk, nil
}
到这里,我们也能得到结论:
解码器本质是:unstructured.UnstructuredJSONScheme;
解码后Obj对象:可以是我们的 Pod/Deployment/Service 等各类资源;
gvk 是 Group Version Kind等信息的缩写(后面会专门讲一下GVK和GVR,这两个概念在k8s中非常重要);
4、m.clientFn(gvk.GroupVersion()) 中的clientFn是啥,啥时候设置的?
有了上面第3点的讲解,看这个就容易很多了,知道了入口的位置,我们直接看 b.getClient 方法被调用时,会做些什么?
func (b *Builder) getClient(gv schema.GroupVersion) (RESTClient, error) {
var (
client RESTClient
err error
)
switch {
case b.fakeClientFn != nil:
client, err = b.fakeClientFn(gv)
case b.negotiatedSerializer != nil:
client, err = b.clientConfigFn.clientForGroupVersion(gv, b.negotiatedSerializer)
default:
// 我们肯定会进入这个分支,其实这里就已经把client初始化差不多了
client, err = b.clientConfigFn.unstructuredClientForGroupVersion(gv)
}
if err != nil {
return nil, err
}
// 添加一些transforms转化器对client进行一些增强,比如:鉴权、转化等操作,有点像过滤器或拦截器
return NewClientWithOptions(client, b.requestTransforms...), nil
}
跟踪创建Client的核心方法:b.clientConfigFn.unstructuredClientForGroupVersion(),我看得是否有点太深了^_^,我们就简单确认以下几点:
-
client的具体类型;
-
baseUrl、apiPath等信息;(具体的请求路径可能不可能在Client中确定,而是应该由具体的Resouce确定)
func (clientConfigFn ClientConfigFunc) unstructuredClientForGroupVersion(gv schema.GroupVersion) (RESTClient, error) {
cfg, err := clientConfigFn()
if err != nil {
return nil, err
}
cfg.ContentConfig = UnstructuredPlusDefaultContentConfig()
cfg.GroupVersion = &gv
// k8s中有api(普通api)和apis(具有分组信息的api集合)
if len(gv.Group) == 0 {
cfg.APIPath = "/api"
} else {
cfg.APIPath = "/apis"
}
// 根据cfg配置,得到RestClient
return rest.RESTClientFor(cfg)
}
继续深入跟踪rest.RESTClientFor(cfg)方法,我们就能清楚地找到我们需要的答案:
func RESTClientFor(config *Config) (*RESTClient, error) {
if config.GroupVersion == nil {
return nil, fmt.Errorf("GroupVersion is required when initializing a RESTClient")
}
if config.NegotiatedSerializer == nil {
return nil, fmt.Errorf("NegotiatedSerializer is required when initializing a RESTClient")
}
// 这里我们得到了我们需要的baseURL, apiPath
baseURL, versionedAPIPath, err := defaultServerUrlFor(config)
if err != nil {
return nil, err
}
transport, err := TransportFor(config)
if err != nil {
return nil, err
}
// 我们想知道的Client的具体类型:创建了一个httpClient
var httpClient *http.Client
if transport != http.DefaultTransport {
httpClient = &http.Client{Transport: transport}
if config.Timeout > 0 {
httpClient.Timeout = config.Timeout
}
}
rateLimiter := config.RateLimiter
if rateLimiter == nil {
qps := config.QPS
if config.QPS == 0.0 {
qps = DefaultQPS
}
burst := config.Burst
if config.Burst == 0 {
burst = DefaultBurst
}
if qps > 0 {
rateLimiter = flowcontrol.NewTokenBucketRateLimiter(qps, burst)
}
}
var gv schema.GroupVersion
if config.GroupVersion != nil {
gv = *config.GroupVersion
}
clientContent := ClientContentConfig{
AcceptContentTypes: config.AcceptContentTypes,
ContentType: config.ContentType,
GroupVersion: gv,
Negotiator: runtime.NewClientNegotiator(config.NegotiatedSerializer, gv),
}
// 所以最终返回的RESTClient其实是对httpClient的封装
restClient, err := NewRESTClient(baseURL, versionedAPIPath, clientContent, rateLimiter, httpClient)
if err == nil && config.WarningHandler != nil {
restClient.warningHandler = config.WarningHandler
}
return restClient, err
}
其中baseURL的策略:
func defaultServerUrlFor(config *Config) (*url.URL, string, error) {
hasCA := len(config.CAFile) != 0 || len(config.CAData) != 0
hasCert := len(config.CertFile) != 0 || len(config.CertData) != 0
defaultTLS := hasCA || hasCert || config.Insecure
host := config.Host
// baseURL如果配置了HOST,那就是host值,如果没有配置,那就是localhost
if host == "" {
host = "localhost"
}
if config.GroupVersion != nil {
return DefaultServerURL(host, config.APIPath, *config.GroupVersion, defaultTLS)
}
return DefaultServerURL(host, config.APIPath, schema.GroupVersion{}, defaultTLS)
}
到这里我们就能得到结论:
baseUrl:如果配置中有Host,就是在合格Host,如果没有,那么就是localhost,关于这个Host是何时设置,这个点,花了我很长时间,才算理清,后面会单独讲一下;
apiPath:可能是普通api,也可能是api分组,具体就是看传入进来的GroupVersion中的Group是否有值;
client的具体类型:HttpClient,所有我们就清楚了,kubectl与apiServer之间的通讯,其实是靠httpClient远程调用完成的;
5、m.restMapperFn()什么时候设置的,info.Mapping中到底存放的是什么?
上面讲过,restMapperFn() 方法设置的入口也还是在 r := f.NewBuilder().Unstructured() 中:
func (b *Builder) Unstructured() *Builder {
if b.mapper != nil {
b.errs = append(b.errs, fmt.Errorf("another mapper was already selected, cannot use unstructured types"))
return b
}
b.objectTyper = unstructuredscheme.NewUnstructuredObjectTyper()
b.mapper = &mapper{
localFn: b.isLocal,
restMapperFn: b.restMapperFn, // 这里为resrMapperFn进行了赋值,根据命名,我们也能知道,这是一个方法;
clientFn: b.getClient, // 为clientFn进行了,赋值,根据命令我们也能知道,这是一个方法,需要被调用时,才会返回具体的Client对象
decoder: &metadataValidatingDecoder{unstructured.UnstructuredJSONScheme}, // 这里为decoder进行了赋值
}
return b
}
而这个 b.restMapperFn 是一个变量,他的方法体是何时定义的呢,肯定得往前找,其实就在 r:=f.NewBuilder() 中:
func (f *factoryImpl) NewBuilder() *resource.Builder {
return resource.NewBuilder(f.clientGetter)
}
func NewBuilder(restClientGetter RESTClientGetter) *Builder {
categoryExpanderFn := func() (restmapper.CategoryExpander, error) {
discoveryClient, err := restClientGetter.ToDiscoveryClient()
if err != nil {
return nil, err
}
return restmapper.NewDiscoveryCategoryExpander(discoveryClient), err
}
// newBuilder的第二个参数,正是restMapperFn,所以这样就形成了传递
// 实际是一个DeferredDiscoveryRESTMapper
return newBuilder(
restClientGetter.ToRESTConfig,
(&cachingRESTMapperFunc{delegate: restClientGetter.ToRESTMapper}).ToRESTMapper,
(&cachingCategoryExpanderFunc{delegate: categoryExpanderFn}).ToCategoryExpander,
)
}
当我们在 infoForData() 方法中调用时:
if m.localFn == nil || !m.localFn() {
// 先获取到了一个具体的RESTMapper(DeferredDiscoveryRESTMapper)
// DeferredDiscoveryRESTMapper的特点是能够根据运行时环境动态地获取和更新 API 资源的映射关系
restMapper, err := m.restMapperFn()
if err != nil {
return nil, err
}
// 通过上面获取到的DeferredDiscoveryRESTMapper,传入GroupKind和Version,可以得到具体的RestMapping映射关系
mapping, err := restMapper.RESTMapping(gvk.GroupKind(), gvk.Version)
if err != nil {
return nil, fmt.Errorf("unable to recognize %q: %v", source, err)
}
ret.Mapping = mapping
// 在f.NewBuilder().Unstructured() 时,定义了b.mapper.clientFn = b.getClient
// 所以这里才可以直接调用执行:得到最终需要的RestClient
client, err := m.clientFn(gvk.GroupVersion())
if err != nil {
return nil, fmt.Errorf("unable to connect to a server to handle %q: %v", mapping.Resource, err)
}
ret.Client = client
}
到这里,我们那可以得到结论:
默认的映射器实现是 DeferredDiscoveryRESTMapper,它在 f.NewBuilder() 期间就已经确定了;
meta.RESTMapping是一个结构体类型,用于存储资源与 API 路径的映射关系信息,作用就是根据 GVR 或者 GVK 确定最终的API路径;
到这里才总算差不多把一个Visitor理清,但是靠一篇博客肯定不可能覆盖到所有的点,但是对于理解整个大体流程,肯定是有很大帮助的,kubernetes是一个非常牛X的项目,代码封装得也非常得好,所以为了理清这些点,需要来回反复地扒代码,非常耗精力。
理清楚Visitor的输入参数Info的由来,再去看调用的函数体 func() 就完全不费力啦!
四、r.Visit(func(info *resource.Info, err error) error {}内部方法体
其实明确了入参 info 的各属性细节,再看 func(){} 方法体,就几乎没有任何难度了!
这里贴了最核心的方法体:
// 通过Helper工具类,封装上info中的一些核心信息,最终通过 Create() 完成对api-server的远程api调用,从而完成create操作 obj, err := resource. // info.client:是初始化好的RESTClient客户端 // info.Mapping:是资源与API的映射关系 NewHelper(info.Client, info.Mapping). DryRun(o.DryRunStrategy == cmdutil.DryRunServer). WithFieldManager(o.fieldManager). // info.Namespace:名称空间 // info.Object:请求的对象体(也就是我们mydeployment.yaml解析出来的对象 - 需要创建的资源) Create(info.Namespace, true, info.Object)
跟踪 Create() 方法:
func (m *Helper) Create(namespace string, modify bool, obj runtime.Object) (runtime.Object, error) {
return m.CreateWithOptions(namespace, modify, obj, nil)
}
func (m *Helper) CreateWithOptions(namespace string, modify bool, obj runtime.Object, options *metav1.CreateOptions) (runtime.Object, error) {
if options == nil {
options = &metav1.CreateOptions{}
}
if m.ServerDryRun {
options.DryRun = []string{metav1.DryRunAll}
}
if m.FieldManager != "" {
options.FieldManager = m.FieldManager
}
if modify {
// Attempt to version the object based on client logic.
version, err := metadataAccessor.ResourceVersion(obj)
if err != nil {
// We don't know how to clear the version on this object, so send it to the server as is
return m.createResource(m.RESTClient, m.Resource, namespace, obj, options)
}
if version != "" {
if err := metadataAccessor.SetResourceVersion(obj, ""); err != nil {
return nil, err
}
}
}
// 1. RESTClient 与kube-apiserver交互的RESTful风格的客户端
// 2. runtime.Object 资源对象的抽象,包括Pod/Deployment/Service等各类资源
// 注意:m.Resource不是我们要创建的资源,而是API路径,如deployments
return m.createResource(m.RESTClient, m.Resource, namespace, obj, options)
}
func (m *Helper) createResource(c RESTClient, resource, namespace string, obj runtime.Object, options *metav1.CreateOptions) (runtime.Object, error) {
// 所以,kubectl create的最终是通过RESTClient给Api-Server发送了一个Post命令,
// 请求体就是runtime.Object,即资源对象的抽象,包括Pod/Deployment/Service等各类资源
return c.Post().
NamespaceIfScoped(namespace, m.NamespaceScoped).
Resource(resource).
VersionedParams(options, metav1.ParameterCodec).
Body(obj).
Do(context.TODO()).
Get()
}
其实光对着纯静态代码去讲会很抽象,我在这最后,贴一个k8s官方的deployments的create API地址和截图:

通过这个图,就应该很清楚,真正的请求体是啥了!
最后:总结:
k8s的代码非常好,封装得非常优秀,因此看起来非常困难,看源码量力而为,明确自己的目标,反正我的目标就是对k8s的原理能有更深刻的理解。
这篇博客花了我很长的时间,因为我是那种喜欢钻牛角尖的人,坑越挖越深、越挖越大,越挖越多^_^!
最后,我做了一个看似简单的总结:
当我们写了一段命令: kubectl create -f mydeployment.yaml 后,kubectl做了些啥?
简单地讲,就是封装出一个Rest请求,把需求提交给api-server,api-server成功响应后,打印一个成功日志,后续就不是自己的事情了。