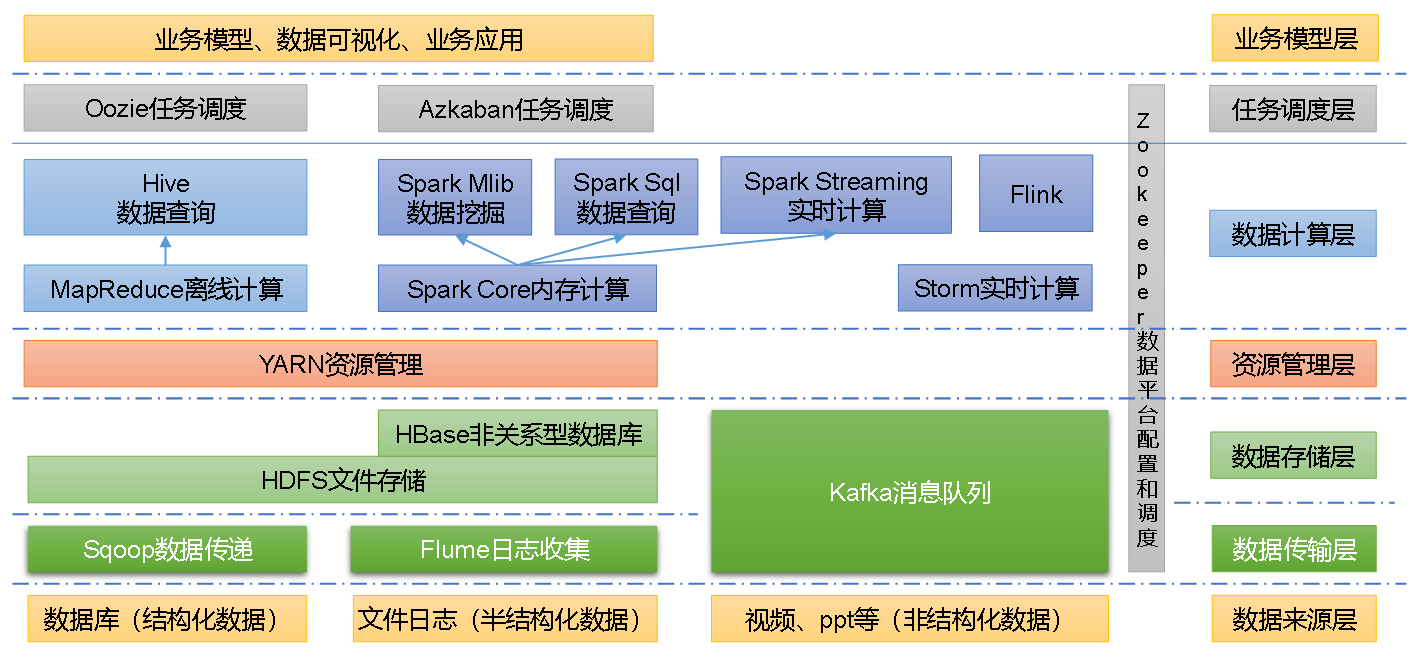
我使用的版本为Hadoop3.1.3,下载地址为:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
一、集群规划与配置
1、主机名/资源分配对应表:
| hadoop102 |
hadoop103 | hadoop104 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
原则:
NameNode与SecondaryNameNode不要部署在同一个节点上(起不到容灾备份的作用)
ResourceManager很消耗内存,不要与NameNode以及SecondaryNameNode部署在同一个节点上;
2、Hadoop官方配置文件说明:
Hadoop配置文件分为2类:默认配置文件 + 自定义配置文件;
只有当用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应的属性值!
-
默认配置文件:
要获取的默认配置文件 文件存放在Haddop的jar包中的位置 [core-default.xml] hadoop-common-3.1.3.jar/core-default.xml [hdfs-default.xml] hadoop-hdfs-3.1.3.jar/hdfs-default.xml [mapred-default.xml] hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml [yarn-default.xml] hadoop-yarn-common-3.1.3.jar/yarn-default.xml -
自定义配置文件:
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
二、安装单机版Hadoop,本地模式运行完成官方demo程序wordcount
1、将下载好的Hadoop3.1.3压缩文件,拷贝到hadoop102机器/opt/software目录:
[jiguiquan@hadoop102 ~]$ cd /opt/software/ [jiguiquan@hadoop102 software]$ ls hadoop-3.1.3.tar.gz jdk-8u211-linux-x64.tar.gz
2、将Hadoop压缩文件解压到/opt/module/目录下:
[jiguiquan@hadoop102 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ [jiguiquan@hadoop102 software]$ cd /opt/module/ [jiguiquan@hadoop102 module]$ ls hadoop-3.1.3 jdk8
3、将hadoop命令,添加到环境变量:
[jiguiquan@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh # 添加一下配置项 export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
使配置生效:
[jiguiquan@hadoop102 ~]$ source /etc/profile
此时,hadoop命令即可使用:
[jiguiquan@hadoop102 ~]$ hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
4、本地模式DEMO——wordcount:
创建wc输入文件夹,并写入测试文件:
[jiguiquan@hadoop102 hadoop-3.1.3]$ mkdir wcinput [jiguiquan@hadoop102 hadoop-3.1.3]$ cd wcinput/ [jiguiquan@hadoop102 wcinput]$ vim word.txt # 内容如下 jiguiquan jiguiquan hanyue hanyue hanyue canglaoshi huge huge
使用官方演示jar包,运行wordcount程序:
[jiguiquan@hadoop102 hadoop-3.1.3]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput/
程序运行完成后,我们可以查看输出文件:
[jiguiquan@hadoop102 hadoop-3.1.3]$ ll wcoutput/ 总用量 4 part-r-00000 #实际结果 _SUCCESS #标记 [jiguiquan@hadoop102 hadoop-3.1.3]$ cat wcoutput/part-r-00000 canglaoshi 1 hanyue 3 huge 2 jiguiquan 2
三、Hadoop集群启动前的配置
先在Hadoop102上进行配置,之后使用xsync命令同步到hadoop103和hadoop104
1、配置核心配置文件core-site.xml:
# cd $HADOOP_HOME/etc/hadoop/ cd /opt/module/hadoop-3.1.3/etc/hadoop
修改core-site.xml,在<configuration>标签内配置以下内容:
<configuration> <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录,不存在则自动创建 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为jiguiquan --> <property> <name>hadoop.http.staticuser.user</name> <value>jiguiquan</value> </property> </configuration>
2、配置HDFS配置文件hdfs-site.xml:
<configuration> <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> </configuration>
3、配置map-reduce配置文件mapred-site.xml:
<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4、配置yarn配置文件yarn-site.xml:
<configuration> <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承,在源默认值的基础上,增加了HADOOP_MAPRED_HOME,3.2之后得版本将不需要配置 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
5、通过xsync命令快速将hadoop102上的hadoop安装目录同步到hadoop103和hadoop104:
[jiguiquan@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/
6、使用root用户将 /etc/profile.d/ 目录同步到 hadoop103和hadoop104:
[root@hadoop102 hadoop]# xsync /etc/profile.d/
7、在hadoop103和hadoop104机器使hadoop环境变量生效,并检查:
[jiguiquan@hadoop103 ~]$ source /etc/profile [jiguiquan@hadoop103 ~]$ hadoop version Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
8、配置workers:
[jiguiquan@hadoop102 hadoop]$ vim workers # 内容如下: hadoop102 hadoop103 hadoop104 ## 注意:不允许有空格或者空白行
同步:
[jiguiquan@hadoop102 hadoop]$ xsync ./
四、启动Hadoop集群与访问
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(因为hadoop102节点是我们规划的NameNode节点)—— 清空账本
(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。
因此,如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
1、在hadoop102节点格式化NameNode:
[jiguiquan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
初始化完成后,会在$HADOOP_HOME下生成一个data和logs目录:
[jiguiquan@hadoop102 hadoop-3.1.3]$ tree data/ data/ └── dfs └── name └── current ├── fsimage_0000000000000000000 ├── fsimage_0000000000000000000.md5 ├── seen_txid └── VERSION [jiguiquan@hadoop102 hadoop-3.1.3]$ tree logs/ logs/ └── SecurityAuth-jiguiquan.audit
2、在配置了NameNode的节点hadoop102启动HDFS:
[jiguiquan@hadoop102 hadoop-3.1.3]$ start-dfs.sh Starting namenodes on [hadoop102] Starting datanodes hadoop104: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. hadoop103: WARNING: /opt/module/hadoop-3.1.3/logs does not exist. Creating. Starting secondary namenodes [hadoop104]
3、在配置了ResourceManager的节点hadoop103启动YARN:
[jiguiquan@hadoop103 hadoop-3.1.3]$ start-yarn.sh Starting resourcemanager Starting nodemanagers
4、添加 jpsall 命令,方便监听服务状态:
[jiguiquan@hadoop102 hadoop-3.1.3]$ cd /home/jiguiquan/bin/ [jiguiquan@hadoop102 bin]$ vim jpsall [jiguiquan@hadoop102 bin]$ chmod +x jpsall # jpsall脚本内容如下: #!/bin/bash for host in hadoop102 hadoop103 hadoop104 do echo =============== $host =============== ssh $host jps done
将jpsall脚本分发到hadoop103和hadoop104:
[jiguiquan@hadoop102 bin]$ xsync jpsall
5、使用jpsall命令查看集群三个节点上的程序运行情况:
[jiguiquan@hadoop102 bin]$ jpsall =============== hadoop102 =============== 3650 NodeManager 3349 DataNode 3196 NameNode 3919 Jps =============== hadoop103 =============== 3153 Jps 2553 ResourceManager 2683 NodeManager 2366 DataNode =============== hadoop104 =============== 2339 DataNode 2441 SecondaryNameNode 2810 Jps 2556 NodeManager
与文章顶部的规划进行对比:

对比后,部署没有问题!
6、浏览器访问2个常用页面:
-
访问HDFS的NameNode:http://hadoop102:9870/

-
访问YARN的ResourceManager:http://hadoop103:8088/

五、Hadoop的简单使用和拓展配置
1、使用命令行上传文件到hdfs:
[jiguiquan@hadoop102 ~]$ pwd /home/jiguiquan [jiguiquan@hadoop102 ~]$ ls bin test [jiguiquan@hadoop102 ~]$ hadoop fs -put test /test 2023-03-15 18:51:01,412 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2023-03-15 18:51:02,389 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false 2023-03-15 18:51:02,437 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
查看刚刚上传的3个文件:
[jiguiquan@hadoop102 ~]$ hadoop fs -get /test get: `test/a.txt': File exists get: `test/b.txt': File exists get: `test/testfile.txt': File exists
通过浏览器查看:

2、我们尝试上传一个大文件:
[jiguiquan@hadoop102 ~]$ hadoop fs -put /opt/software/hadoop-3.1.3.tar.gz /test
此时我们再通过WEB页面访问,将会发现此大文件被切分为了3片,每片最大大小为128M(默认):

3、使用YARN模式运行wordcount示例的mapreduce程序:
准备input文件:
[jiguiquan@hadoop102 ~]$ ls /opt/module/hadoop-3.1.3/wcinput/ word.txt [jiguiquan@hadoop102 ~]$ hadoop fs -put /opt/module/hadoop-3.1.3/wcinput/ /wcinput 2023-03-15 19:02:32,742 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
使用集群模式运行wordcount示例程序:
[jiguiquan@hadoop102 ~]$ hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
由于当前MapReduce是在YARN上运行的,所以我们再YARN的ResourceManager对应的页面,可以看到当前MapReduce任务:
但是,当我们点击History链接时,会显示无法访问:那是因为我们没有开启“历史服务器”的配置!
4、配置mapreduce的“历史服务器”:
修改mapreduce的自定义配置文件mapred-site.xml:
<configuration> <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址:内容通讯端口 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- 历史服务器web端地址:对外暴露的WEB页面地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property> </configuration>
同步mapred-site.xml到hadoop103和hadoop104:
[jiguiquan@hadoop102 hadoop]$ xsync mapred-site.xml
在hadoop102节点上手动启动“历史服务器”:
[jiguiquan@hadoop102 hadoop]$ mapred --daemon start historyserver [jiguiquan@hadoop102 hadoop]$ jps 3650 NodeManager 3349 DataNode 4875 Jps 3196 NameNode 4813 JobHistoryServer
此时,当我们再次点击History链接时,即可进入以下界面:
 但是,当我们点击页面中的logs链接时,依然无法访问,那是因为我们还没有开启“日志聚集功能”!
但是,当我们点击页面中的logs链接时,依然无法访问,那是因为我们还没有开启“日志聚集功能”!
5、配置YARN的“日志聚集功能”:
之所以要有日志聚集功能,是因为在运行过程中,日志是在不同的节点上的,所以需要有一个专门收集这些分散的日志!

配置YARN的自定义配置文件yarn-site.xml,在原基础上增加以下配置:
<!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址,和历史服务器节点放在一起hadoop102 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
同步yarn-site.xml到hadoop103和hadoop104上:
[jiguiquan@hadoop102 hadoop]$ xsync yarn-site.xml
需要重启历史服务器、以及YARN的ResourceManager服务:
# 在hadoop102节点关闭historyserver: [jiguiquan@hadoop102 hadoop]$ mapred --daemon stop historyserver ## 在hadoop103节点关闭yarn: [jiguiquan@hadoop103 hadoop-3.1.3]$ stop-yarn.sh
由于HDFS不受影响,所以我们不需要重启HDFS:
[jiguiquan@hadoop103 hadoop-3.1.3]$ jpsall =============== hadoop102 =============== 3349 DataNode 5109 Jps 3196 NameNode =============== hadoop103 =============== 3587 Jps 2366 DataNode =============== hadoop104 =============== 2339 DataNode 2441 SecondaryNameNode 3244 Jps
反向再重启YARN服务、和历史服务器:
[jiguiquan@hadoop103 hadoop-3.1.3]$ start-yarn.sh Starting resourcemanager Starting nodemanagers [jiguiquan@hadoop102 hadoop]$ mapred --daemon start historyserver [jiguiquan@hadoop102 hadoop]$ jpsall =============== hadoop102 =============== 3349 DataNode 5353 JobHistoryServer 3196 NameNode 5182 NodeManager 5422 Jps =============== hadoop103 =============== 4209 Jps 3720 ResourceManager 2366 DataNode 4031 NodeManager =============== hadoop104 =============== 2339 DataNode 3462 Jps 2441 SecondaryNameNode 3324 NodeManager
6、之后新的任务的日志将会被聚集:

到这里,整个Hadoop集群的部署工作就算全部完成了!
六、常用启停命令,以及自定义命令
1、整体启停HDFS和YARN:
start-dfs.sh/stop-dfs.sh start-yarn.sh/stop-yarn.sh
2、各个组件逐一启停:
hdfs --daemon start/stop namenode/datanode/secondarynamenode yarn --daemon start/stop resourcemanager/nodemanager mapred --daemon start/stop historyserver
3、自定义编写整个hadoop集群的启停脚本(包括HDFS、YARN、HistoryServer):
[jiguiquan@hadoop102 hadoop]$ cd /home/jiguiquan/bin/ [jiguiquan@hadoop102 bin]$ vim myhadoop.sh [jiguiquan@hadoop102 bin]$ chmod +x myhadoop.sh
myhadoop.sh脚本内容如下:
#!/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac
分发myhadoop.sh脚本到hadoop103和hadoop104:
[jiguiquan@hadoop102 bin]$ xsync myhadoop.sh
4、测试 myhadoop.sh 自定义脚本:
查看集群当前服务状态:
[jiguiquan@hadoop102 ~]$ jpsall =============== hadoop102 =============== 5729 Jps 3349 DataNode 5353 JobHistoryServer 3196 NameNode 5182 NodeManager =============== hadoop103 =============== 4499 Jps 3720 ResourceManager 2366 DataNode 4031 NodeManager =============== hadoop104 =============== 2339 DataNode 2441 SecondaryNameNode 3324 NodeManager 3695 Jps
停止Hadoop集群:
[jiguiquan@hadoop102 ~]$ myhadoop.sh stop =================== 关闭 hadoop集群 =================== --------------- 关闭 historyserver --------------- --------------- 关闭 yarn --------------- Stopping nodemanagers Stopping resourcemanager --------------- 关闭 hdfs --------------- Stopping namenodes on [hadoop102] Stopping datanodes Stopping secondary namenodes [hadoop104]
再次查看集群服务状态:
[jiguiquan@hadoop102 ~]$ jpsall =============== hadoop102 =============== 6311 Jps =============== hadoop103 =============== 4851 Jps =============== hadoop104 =============== 3890 Jps
启动Hadoop集群:
[jiguiquan@hadoop102 ~]$ myhadoop.sh start =================== 启动 hadoop集群 =================== --------------- 启动 hdfs --------------- Starting namenodes on [hadoop102] Starting datanodes Starting secondary namenodes [hadoop104] --------------- 启动 yarn --------------- Starting resourcemanager Starting nodemanagers --------------- 启动 historyserver ---------------
再次查看集群服务状态:
[jiguiquan@hadoop102 ~]$ jpsall =============== hadoop102 =============== 6656 DataNode 7120 JobHistoryServer 6946 NodeManager 6500 NameNode 7194 Jps =============== hadoop103 =============== 5108 ResourceManager 4923 DataNode 5420 NodeManager 5596 Jps =============== hadoop104 =============== 4161 NodeManager 4296 Jps 3962 DataNode 4075 SecondaryNameNode
很好使!
整个Hadoop的集群搭建工作就到这里了!